Introduction:
In the world of chat models and large language models (LLMs), there has been a recent surge in the release of new models with claims of improved performance and capabilities. However, a new study conducted by a research team from Alibaba and Singapore University challenges the notion of significant progress in this domain. The study introduces a new leaderboard for instruction-tuned LLMs, shedding light on the performance of various models in the “problem solving” context.
To delve deeper into the study, you can access the full
Scientific paper: arXiv
The Chat Model Landscape:
The study focuses on a particular class of models that have gained attention recently, including Vicuna, Alpaca, Dolly, and the widely known ChatGPT. These models have been the center of attention, creating a buzz in the industry and among researchers. However, the research team aimed to evaluate their performance against a more established model: Flan-T5.
The Surprising Results:
The benchmarking results for “problem solving” tasks yielded intriguing findings. While ChatGPT emerged as the best-performing model on average, it is the 3rd ranked model, Flan-T5, that catches attention. Flan-T5 is a base model based on T5, which was initially released in 2019. It has been fine-tuned with instructions to enhance its performance and effectiveness in specific tasks.
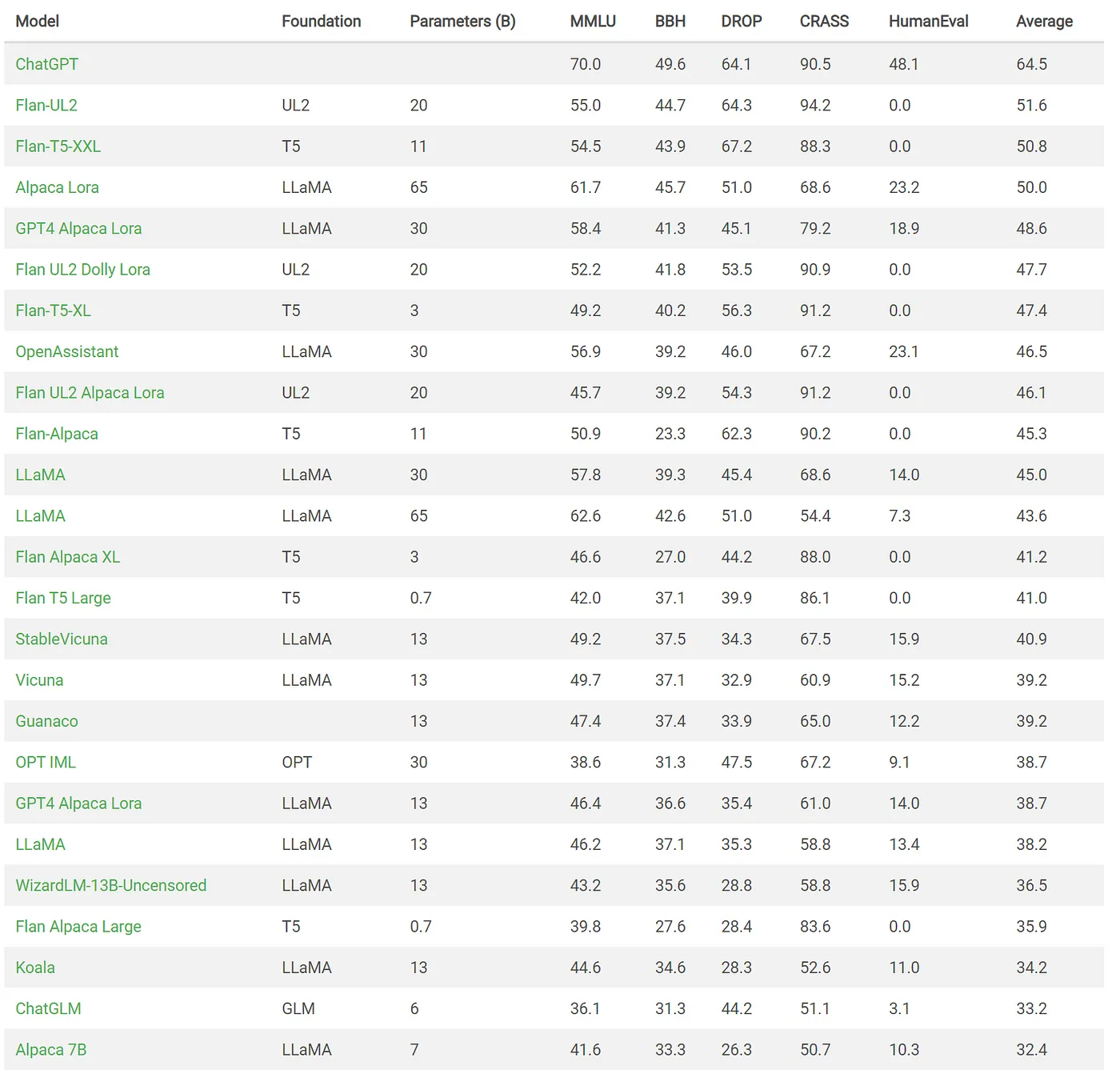
Source: https://declare-lab.net/instruct-eval/ (June 14th, 2023)
Surpassing the Competition:
What makes Flan-T5 remarkable is its ability to outperform other LLaMa (large language model) and OPT-based models, despite being significantly smaller in terms of the number of parameters. The study highlights that Flan-T5’s performance is particularly impressive when compared to the billion-parameter models in the same domain.
A Shift in Perspective:
This study marks a significant turning point in the evaluation of chat models. Unlike previous comparisons that primarily focused on recent models within a limited timeframe, this research introduces a broader perspective by including a model from 2019. The findings challenge the notion of relentless progress in the chat model landscape and open up new avenues for understanding the strengths and limitations of different model architectures.
Conclusion:
As the excitement around new chat models continues to grow, it is essential to critically evaluate their performance and compare them to established models for a comprehensive understanding of their capabilities. The study by the Alibaba and Singapore University research team showcases that models based on T5, even from 2019, still exhibit remarkable performance compared to the latest billion-parameter models. This research sparks new discussions and encourages further exploration into the advancements and limitations of chat models.
With this new perspective, the field of natural language processing (NLP) can continue to evolve, fueled by meaningful comparisons and insights from both recent and established models.
Note: The results and rankings mentioned in this article are based on the specific research study conducted by the Alibaba and Singapore University research team. Further research and evaluations may yield different rankings and conclusions.